《大数据: Hadoop(HDFS) 读写数据流程分析》
本文共 269 字,大约阅读时间需要 1 分钟。
一、HDFS的写数据正常流程
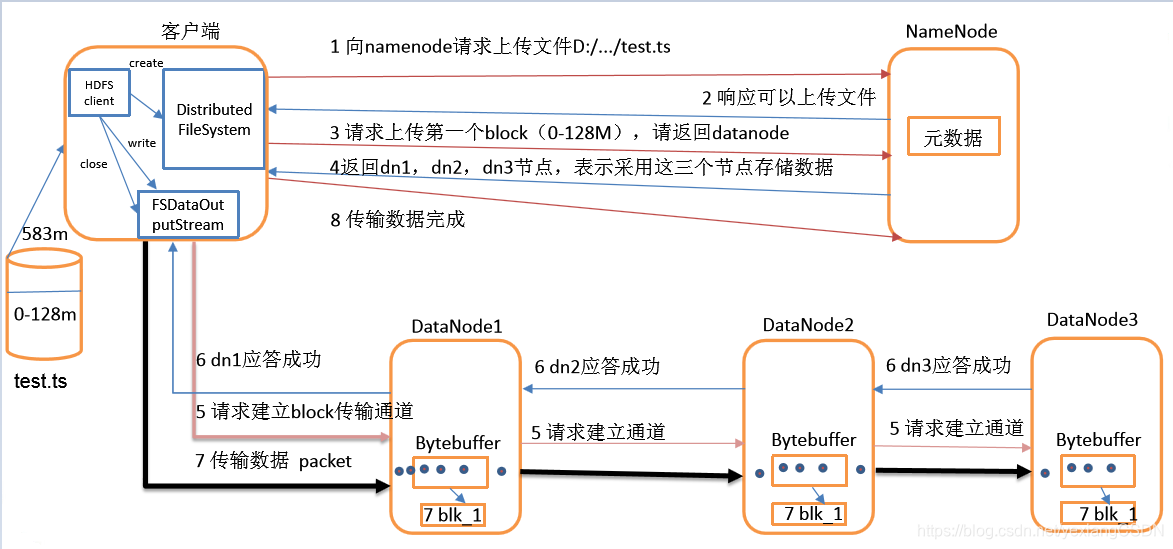
- ①. 服务端启动HDFS中的NN和DN进程
- ②. 客户端创建一个分布式文件系统客户端,由客户端向NN发送请求,请求上传文件
- ③. NN处理请求,检查客户端是否有权限上传,路径是否合法等
- ④. 检查通过,NN响应客户端可以上传
- ⑤. 客户端根据自己设置的块大小,开始上传第一个块,默认0-128M,NN根据客户端上传文件的副本数(默认为3),根据机架感知策略选取指定数量的DN节点返回
- ⑥. 客户端根据返回的DN1,DN2,DN3节点,请求建立传输通道客户端向最近(网络举例最近)的DN1节点发起通道建立请求,
转载地址:http://lkut.baihongyu.com/
你可能感兴趣的文章